Why do developers hate code coverage? And why they should not hate it!
I find it interesting that you do see people raging against code coverage. A prevalent opinion out there is “Oh, but you know, code coverage is worthless; if I write a test case with no assertions, I achieve 100% coverage, but I am not testing anything!”
They are not wrong! If your tests have no assertions, they will not be testing anything, and yet, the production code will be exercised. However, I find that a flawed argument. It assumes the very worst (unrealistic) scenario possible. If you are really writing test suites with no assertions, you have bigger problems to take care of before you can enjoy the benefits of structural testing. Maybe your code isn’t designed with testability in mind, but that’s something for another time.
Between the lines, people use such an argument to explain why you should not look at the coverage number blindly. After all, it can mislead you. I fully agree. Here, I believe the misconception is about how people see code coverage. For many of them, code coverage is about a number you should achieve. If your goal is to achieve 95% branch coverage, no matter what, you may end up writing less useful test cases. You end up gaming the metric.
However, that is not how coverage coverage is meant to be used. Code coverage is an awesome tool to help you augment the tests you created based on the requirements of the program. I describe it better in the book (chapter 3 on structural testing), but let me try and summarize it.
Your initial set of tests should be derived from the specification of the program. What does it need to do? Are there corner cases based on the requirements? Are there special cases that the program needs to handle? And etc. Once you engineered all the tests you could see, you now may want to use coverage as a way “to see if you forgot something”.
Imagine the coverage report telling you that you missed a branch. When that happens, the question you should ask yourself is: “why didn’t I see this when I was creating the tests?”. Maybe you simply forgot about it. Good, that’s how coverage shows its value. Maybe you did have a reason not to test that case. That’s good again, as the coverage made you reflect about it.
Once you looked at everything that’s covered and everything that’s not covered, you are done! Note that I didn’t really mention the code coverage magical number that everybody focuses when talking about it. The number really doesn’t mean much once you start seeing coverage in this way. Achieving a high coverage number might be just a consequence of you doing that. But again, the purpose is different. If you leave a line uncovered there, it is because you reflect about it and decided not to cover it.
See the image below, extracted from my book. The point 1 there is how you start. You create tests based on what you know about the behavior of the program. Then, you want to augment the tests. How do you do that? By looking at the implementation and looking for uncovered parts of the code.
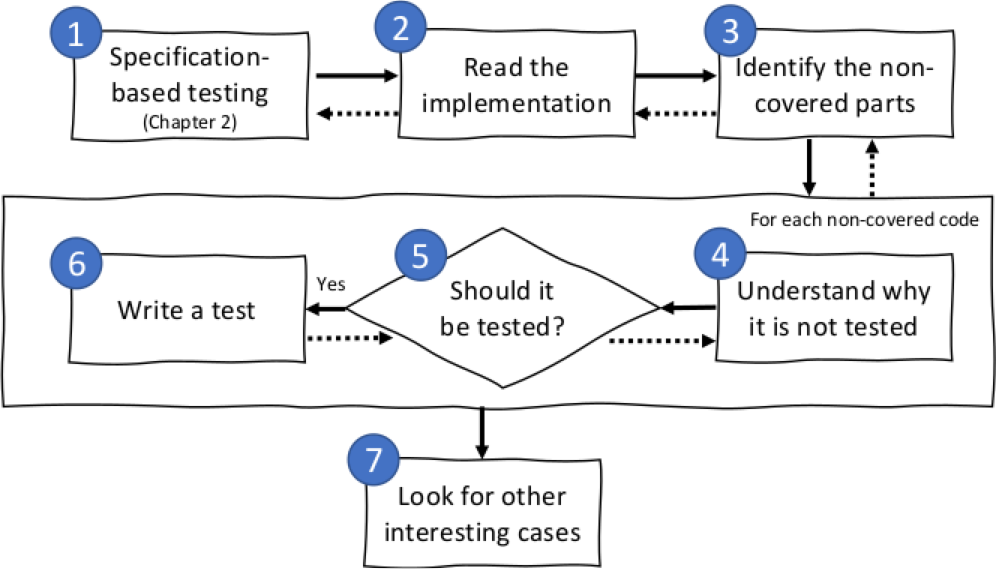
Although the flow may look like you should only do structural testing once you are fully done with the tests from the specs of the program, in practice, this is a super iterative process, as you are the developer writing the production and the test code. The idea is still the same: coverage not as a number, but as a tool to understand if something else should be tested.
Now, of course the code coverage number is not completely useless. Unless you have a very good reason for it, having a super low coverage may indicate that your test suite is poor. In other words, having 90% or 91% coverage makes no difference at all in practice; but having a 10% coverage is definitely an alarm.
Understanding whether structural coverage helps and whether high coverage numbers lead to better tested software has been the goal of many empirical software engineering researchers. Interestingly, while researchers have not yet found a magical coverage number that one should aim for, we see some evidence pointing towards the benefits of structural testing. I quote three such studies.
- First, Hutchins et al.: “Within the limited domain of our experiments, test sets achieving coverage levels over 90% usually showed significantly better fault detection than randomly chosen test sets of the same size. In addition, significant improvements in the effectiveness of coverage-based tests usually occurred as coverage increased from 90% to 100%. However, the results also indicate that 100% code coverage alone is not a reliable indicator of the effectiveness of a test set.”
- Namin and Andrews: “Our experiments indicate that coverage is sometimes correlated with effectiveness when test suite size is controlled for, and that using both size and coverage yields a more accurate prediction of effectiveness than test suite size alone. This, in turn, suggests that both size and coverage are important to test suite effectiveness.”
- Finally, Inozemtseva and Holmes: “We found that there is a low to moderate correlation between coverage and effectiveness when the number of test cases in the suite is controlled for. In addition, we found that stronger forms of coverage do not provide greater insight into the effectiveness of the suite. Our results suggest that coverage, while useful for identifying undertested parts of a program, should not be used as a quality target because it is not a good indicator of test suite effectiveness.”
These results make total sense to me. After all, even with the small code examples we have been exploring in this book, we could see a sort of relationship between covering all the partitions via specification-based testing and covering the entire source code. This means that the opposite is also true: if you cover great parts of the source code, you also cover most of the partitions. Therefore, high coverage implies more partitions being tested.
The empirical results also show that coverage alone is not always a strong indicator of how good a test suite is. Specification-based testing and structural testing complement each other. On the other hand, while 100% coverage does not necessarily mean that the system is properly tested, having very low coverage does mean your system is not being properly tested. Having a system that has, say, 10% coverage, means there is much to be done when it comes to testing.
Finally, I suggest that you read Google’s code coverage best practices, written by Carlos Arguelles, Marko Ivankovic, and Adam Bender, in 2020. Their perceptions are in line with everything we just discussed here.
References
- Monica Hutchins, Herb Foster, Tarak Goradia, and Thomas Ostrand (1994). “Experiments on the effectiveness of dataflow-and control-flow-based test adequacy criteria”. In: Proceedings of 16th International conference on Software engineering. IEEE.
- Akbar Siami Namin and James H Andrews (2009). “The influence of size and coverage on test suite effectiveness”. In: Proceedings of the eighteenth international symposium on Software testing and analysis.
- Laura Inozemtseva and Reid Holmes (2014). “Coverage is not strongly correlated with test suite effectiveness”. In: Proceedings of the 36th international conference on software engineering.